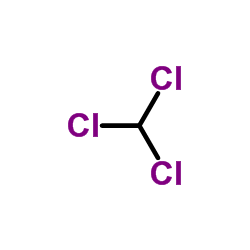
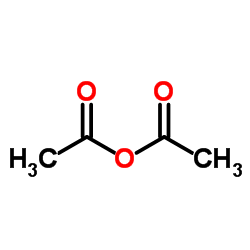
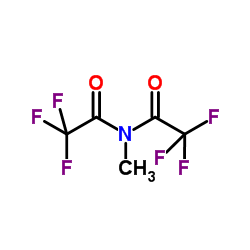
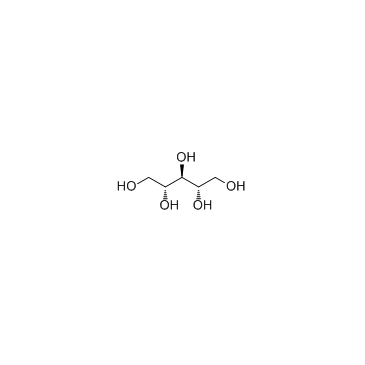
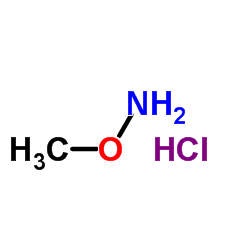
The goal of metabolomics data pre-processing is to eliminate systematic variation, such that biologically-related metabolite signatures are detected by statistical pattern recognition. Although several methods have been developed to tackle the issue of batch-to-batch variation, each method has its advantages and disadvantages. In this study, we used a reference sample as a normalization standard for test samples within the same batch, and each metabolite value is expressed as a ratio relative to its counterpart in the reference sample. We then applied this approach to a large multi-batch data set to facilitate intra- and inter-batch data integration. Our results demonstrate that normalization to a single reference standard has the potential to minimize batch-to-batch data variation across a large, multi-batch data set.